
當6 TOPS不再是極限:米爾RK3576 + Hailo-8,讓高幀率攝像頭真正“實時”
http://www.moduwu.com 2026-04-07 10:53 來源:米爾電子
在邊緣計算領域,算力與實時性之間的博弈從未停止。近期基于 米爾MYD-LR3576 開發(fā)板+ PCIe M.2 接口 Hailo-8 算力卡 進行了一系列深度測試,一組實測數據,或許能幫你重新審視邊緣 AI 的“性能天花板”。

圖:米爾基于RK3576開發(fā)板
一、RK3576 的算力極限在哪里?
RK3576 內置 NPU 由 2 核組成,具備 6 TOPS 算力,在常規(guī)輕量級模型推理中表現不俗。但在實際項目中,我們通過多路并發(fā)測試發(fā)現,當 4 路 YOLOv5 模型同時推理時,NPU 負載率已超過 75%。一旦增加到第5路,整體延遲急劇飆升,系統(tǒng)響應明顯劣化。
在單路推理場景下,YOLOv5(640×640)耗時約 26ms,折算下來僅能穩(wěn)定處理 30fps 的攝像頭數據。
這意味著什么?
當攝像頭升級到 60fps 甚至 120fps 的高幀率場景時,單靠 RK3576 的 NPU 已經無法做到逐幀實時處理。要么丟幀,要么延遲不斷累積——這在工業(yè)高速檢測、智慧交通、機器人導航等對實時性要求嚴苛的應用中,是不可接受的。
二、Hailo-8算力卡介紹
Hailo-8 是一款專為邊緣 AI 推理設計的專用加速器,擁有26TOPS算力,面向嵌入式設備和低功耗場景,提供高效、可擴展的 AI 計算能力。官方網址:https://hailo.ai/。
為什么 Hailo-8 能在相同功耗下實現數倍于傳統(tǒng) NPU 的性能?答案不在算力數字,而在架構:
1. 數據流架構(Dataflow Architecture)
傳統(tǒng) NPU 像“工廠”從倉庫(DDR)來回搬運數據,效率受限于搬運速度。而 Hailo-8 的數據流架構讓數據在芯片內部“流水線式”流動,大幅減少對外部內存的依賴。簡單說:算力不再是瓶頸,內存帶寬才是——而 Hailo-8 繞開了這個瓶頸。
2. 無外部 DRAM 依賴
Hailo-8 不依賴外部大帶寬內存,推理過程中幾乎不與 CPU/NPU 爭搶 DDR 資源。在多路視頻并發(fā)場景下,這意味著系統(tǒng)不會因為“搶內存”而掉幀,整體穩(wěn)定性大幅提升。
三、實測數據:讓性能說話
在相同模型條件下(YOLOv5s):
|
加速模塊/算力卡 |
單幀耗時 |
等效 FPS |
|
RK3576 NPU |
26ms |
~38 FPS |
|
Hailo-8 |
8.241ms |
~121 FPS |
在更復雜模型(YOLOv8s)測試中,Hailo-8算力卡benchmark測試如下:
root@rk3576:~# hailortcli benchmark ./yolov8s.hef
Starting Measurements...
=======
Summary
=======
FPS (hw_only) = 208.543
(streaming) = 208.1
Latency (hw) = 7.03997 ms
Device 0000:01:00.0:
Power in streaming mode (average) = 3.07729 W
(max) = 3.13305 W
7 毫秒的推理延遲意味著:即使是 120fps 的高速攝像頭,系統(tǒng)也能輕松應對,做到逐幀實時處理。
我們還運行了 Hailo-8 自帶的攝像頭實時推理示例,效果如下:
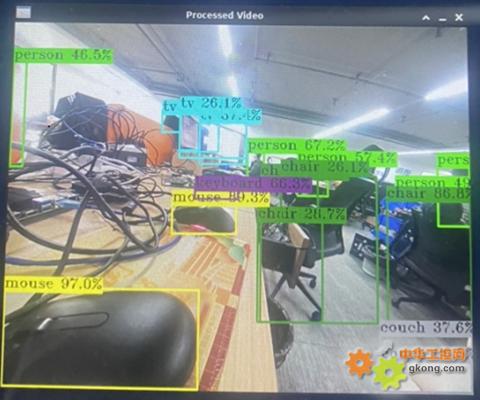
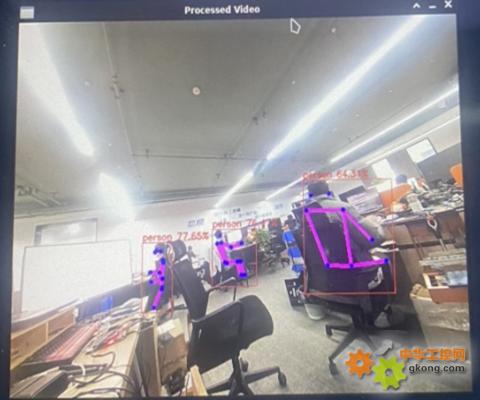
四、應用場景:當實時性成為剛需
這套方案能解決哪些實際問題?我們來看幾個典型場景:
工業(yè)高速視覺檢測:120fps 工業(yè)相機捕捉高速產線上的工件,Hailo-8 的 8ms 推理延遲確保缺陷被實時發(fā)現并剔除,避免漏檢流入下一道工序。
智慧交通卡口:車輛高速通過時,系統(tǒng)需毫秒級完成檢測+識別+跟蹤。208 FPS 的吞吐能力讓單節(jié)點可同時處理多模型,不丟車、不漏牌。
安防邊緣節(jié)點:4 路以上 4K 視頻同時分析,Hailo-8 的高吞吐讓單節(jié)點覆蓋范圍翻倍,大幅降低每路視頻的硬件成本。
五、總結:彈性算力,從容應對高幀率挑戰(zhàn)
通過以上測試,我們可以清晰地看到:
- 引入 Hailo-8 算力卡后,YOLOv5 推理時間縮短至 8ms,YOLOv8實測達到208 FPS 的吞吐量,不僅輕松覆蓋 120fps 攝像頭的全幀率推理,更預留了充足的算力余量。
- 彈性算力,按需選擇:成本敏感項目可單獨使用 RK3576;高幀率、低延遲場景只需增加 Hailo-8 模塊,無需更換主控。
- 突破架構局限,實現真正實時:Hailo-8 的數據流架構將有效算力利用率提升至 80% 以上,配合 RK3576 的 PCIe 2.1 接口,讓推理延遲從毫秒級壓縮至微秒級。
- 為未來預留空間:算法快速迭代的今天,RK3576 + Hailo-8 的組合為未來兩年的算法升級提供了充足的算力冗余,保護客戶的硬件投資。

相關新聞
- ? OpenClaw 秒級上線!JishuShell 適配米爾RK3576開發(fā)板
- ? 新品!從MINI到工業(yè)板:米爾T153開發(fā)板工業(yè)場景全覆蓋
- ? 展會預告!米爾邀您相約德國嵌入式展 2026Embedded World
- ? 新品!高能效,低功耗,TI AM62L經典再進化
- ? 當國產芯遇上機器人:米爾RK3576開發(fā)板的ROS2奇幻之旅
- ? 內置全棧安全,一站式滿足CRA法案與IEC 62443標準——米爾STM32MP257核心板
- ? 新品!AMD Zynq UltraScale+ MPSoC EG異構多處理開發(fā)平臺
- ? 新品!米爾基于全志T153四核異構工業(yè)芯核心板,賦能多元化工業(yè)場景
- ? 從兩輪車儀表到工程機械環(huán)視,米爾電子助力國產 HMI 顯控一體化突圍
- ? 【深度實戰(zhàn)】米爾RK3576開發(fā)板AMP非對稱多核開發(fā)指南:從配置到實戰(zhàn)
編輯精選
- ? 首個人形機器人與具身智能標準體系發(fā)布
- ? 2 月份中國制造業(yè)景氣度創(chuàng)五年來最強勁改善率
- ? 匯川攜手中國聯通發(fā)布Universe平臺
- ? 舍弗勒宣布樂聚為首個中國具身智能合作伙伴,人形機器人走向全球產業(yè)協同
- ? 埃斯頓港股上市,“A+H”雙資本平臺戰(zhàn)略加速國際化布局
- ? 《2025年人形機器人市場研究報告》發(fā)布
- ? ABB機器人攜手英偉達 加速工業(yè)級物理AI規(guī)模化落地
- ? 打造“5G+工業(yè)互聯網”升級版 為智能經濟注入強勁動能
- ? 2026成都國際工業(yè)博覽會開幕,西部智造"向綠向智"加速跑
- ? 康佳特aReady.YOURS提供快速可靠的全定制嵌入式設計
工控原創(chuàng)
- ? ADI:人形機器人爆發(fā)背后,連接與感知仍是關鍵挑戰(zhàn)
- ? 春啟智造新篇!2026年3月工業(yè)自動化資訊全覽
- ? 當AI跨越虛實鴻溝,西門子如何在物理世界重寫工業(yè)規(guī)則?
- ? 會造成工控系統(tǒng)失控等安全風險!工信部旗下單位發(fā)布工業(yè)領域OpenClaw應用風險通報
- ? ABB機器人攜手英偉達 加速工業(yè)級物理AI規(guī)模化落地
- ? 舍弗勒宣布樂聚為首個中國具身智能合作伙伴,人形機器人走向全球產業(yè)協同
- ? 營收首破400億歐元大關 施耐德電氣2025財年交出強勁業(yè)績
- ? 高效電機市場強勁復蘇,2030年規(guī)模預計翻番至31億美元
- ? 美的剝離伺服資產,聚焦核心部件突圍
- ? 六十載創(chuàng)新積淀,ADI開啟邊緣智能新篇章


